最近写的一个脚本,是fork了一个子进程来调用的,内容很简单,就是通过system调用一个exp脚本,exp脚本执行scp命令来拷贝文件。然后百思不得其解的是system调用后没有返回,在system后面的log没有,而且system直接导致我的子进程退出了。然后在开发环境模拟这个问题,死都模拟不出来。但是在线上环境就是必现,搞得我郁闷啊。而且同事用system命令就没问题。
后来偶然就把system改成了exec,没想到就ok了,可以返回了,这简直搞不懂啊。
php的手册里面也只是说明了一些用法上的不同,并没有具体说明深入的区别,这坑爹呢。感觉php做后台的程序还是有些不爽的地方,就像regtickfunctions那个函数一样。
2012年11月5日星期一
2012年8月25日星期六
php安装pcntl
一直以为是要象安装libevent库一样来安装pcntl,但是今天在虚拟机上php -m一看,pcntl已经安装了,估计是apt-get install php5-dev的时候就安装了。这下省事了。
其实pcntl是php的标准库,在php的源代码里面编译来安装的。而libevent是要在pecl的网站下源码编译安装的。
其实pcntl是php的标准库,在php的源代码里面编译来安装的。而libevent是要在pecl的网站下源码编译安装的。
2012年8月24日星期五
PHP安装libevent扩展库
今天一直在看php如何使用epoll模型进行编程。因为之前是用select模型来写得服务器程序,虽然功能无碍,但是第一个版本总是不会让我满意,所以想趁着这段时间比较空闲,把服务器程序用epoll模型重新写一遍。在这之前首先要把libevent的库安装了。
- php的libevent扩展库依赖于原始的libevent库,必须先把libevent库安装了。先用 ls -al /usr/lib | grep libevent 或者 ls -al /usr/local/lib | grep libevent来看看linux是否已经安装了libevent库,发现没有安装。然后就去下载了libevent 2.0版本的源码,解压,进入目录,./configure,make,make install 安装完毕,用ls -al 命令查看发现安装成功。但是是安装到/usr/local/lib目录下面的,所以要用 ln -s /usr/local/lib/libevent-2.0.so /usr/lib/libevent-2.0.so
- 在
http://pecl.php.net/网站把libevnt的扩展包下下来,然后解压缩,进入目录,执行phpize来生成configure文件,./configure,make,make install,安装完成。安装完成后还要在php.ini里面把 extension=libevent.so 这句话加上。结果我发现我有两个php.ini文件,一个是/etc/php5/cli/php.ini,另外一个是/etc/php5/apache2/php.ini文件,不知道写在哪个文件,我就把两个文件都加了那句话。加完还要重启一下apache才行,这点pecl网站都没写。重启的命令:/etc/init.d/apache2 restart。
后来试了一下,貌似要加到cli目录下的php.ini文件里面才行。 - 验证安装:php -m查看库,可以看到libevent。
2012年8月21日星期二
简单的启动和关闭虚拟机的bat文件
为了不要每次在cmd里面输入命令,写了两个简单的bat文件来启动和关闭虚拟机。
1.启动虚拟机(startvm.bat):
@echo off
cd "c:\Program Files\Oracle\VirtualBox"
VBoxManage.exe startvm ubuntu --type headless
exit
2.关闭虚拟机(closevm.bat)
@echo off
cd "c:\Program Files\Oracle\VirtualBox"
VBoxManage.exe controlvm ubuntu poweroff
exit
机器加了2g的内存后现在是4g内存了,当然在32位系统里面只用了3g多。不过一开虚拟机后内存占用居然还是飙到了2.3个G,汗啊。不过在我的ssd加4g内存的条件下,虚拟机速度还是不错的,比以前hdd加2g内存好多了。
1.启动虚拟机(startvm.bat):
@echo off
cd "c:\Program Files\Oracle\VirtualBox"
VBoxManage.exe startvm ubuntu --type headless
exit
2.关闭虚拟机(closevm.bat)
@echo off
cd "c:\Program Files\Oracle\VirtualBox"
VBoxManage.exe controlvm ubuntu poweroff
exit
机器加了2g的内存后现在是4g内存了,当然在32位系统里面只用了3g多。不过一开虚拟机后内存占用居然还是飙到了2.3个G,汗啊。不过在我的ssd加4g内存的条件下,虚拟机速度还是不错的,比以前hdd加2g内存好多了。
排查php占cpu%的一些手段
今天偶然发现php大概有1分钟的时间一直占用100%的cpu,首次碰到这种情况,除了查看程序的log之外就没有想到什么手段来排查了。于是乎google之,找到一些手段,下一步就是把这些手段加到同事写的监控脚本里面。监控脚本的基本思想,每隔一段时间查看cpu的利用率,如果发现是100%的cpu占用,则把这个时刻的各种进程信息grep下来,并到程序log里面根据进程号和时间grep相应的日志。把现场环境grep后发邮件到相关人等。
一些监控的手段:
1.top命令查看cpu利用率。
2.ls -l /proc/进程号/fd/ 查看进程在干嘛
3.strace -p 13827 可以实时的看进程在干嘛
参考文章:php-cgi占用cpu100%的一次排障之旅 以及 PHP-CGI 进程 CPU 100% 与 file_get_contents 函数的关系
一些监控的手段:
1.top命令查看cpu利用率。
2.ls -l /proc/进程号/fd/ 查看进程在干嘛
3.strace -p 13827 可以实时的看进程在干嘛
参考文章:php-cgi占用cpu100%的一次排障之旅 以及 PHP-CGI 进程 CPU 100% 与 file_get_contents 函数的关系
2012年8月19日星期日
LAMP环境搭建
搞了这么久php,今天才算是花时间在笔记本上面搭建了一个lamp环境。其中无非是安装php,apache,mysql,这些在ubuntu下面都是apt-get install来解决了,很方便。这里稍微记录一下。
1.基本的安装:参考了这篇文章:ubuntu安装lamp环境
2.一点补充的安装(phpmyadmin):ubuntu 12.04下LAMP安装配置
3.补充一点,要安装扩展的话,需要phpize,这样来安装:apt-get install php5-dev
4.因为是用的virtualbox来做虚拟机,不想每次都启动gui,所以用命令行方式:在cmd里面,找到virtualbox的安装牡蛎,里面有个程序是vboxmanage,用这个命令来启动
vboxmanage startvm ubuntu --type headless
参考:Linux下虚拟机VirtualBox后台运行
1.基本的安装:参考了这篇文章:ubuntu安装lamp环境
2.一点补充的安装(phpmyadmin):ubuntu 12.04下LAMP安装配置
3.补充一点,要安装扩展的话,需要phpize,这样来安装:apt-get install php5-dev
4.因为是用的virtualbox来做虚拟机,不想每次都启动gui,所以用命令行方式:在cmd里面,找到virtualbox的安装牡蛎,里面有个程序是vboxmanage,用这个命令来启动
vboxmanage startvm ubuntu --type headless
参考:Linux下虚拟机VirtualBox后台运行
2012年8月2日星期四
消除Zendstudio的黄色惊叹号
虽然zend有点慢,不过功能还是比较全的。但是有个问题,有些系统函数都识别不出来,一直提示黄色的惊叹号(比如printf)。在网上搜了一下,兼自己实践,解决方法如下:在新建项目的时候,最后会提示导入哪些库,这时候选择所有的库,项目建好后可以看到黄色的惊叹号就没有了。查看项目文件".buildpath",内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<buildpath>
<buildpathentry kind="con" path="com.zend.php.phpunit.CONTAINER"/>
<buildpathentry kind="con" path="org.eclipse.php.core.LANGUAGE"/>
<buildpathentry kind="src" path=""/>
<buildpathentry kind="con" path="org.zend.php.framework.CONTAINER"/>
<buT67M.gif) ildpath>
ildpath>
<buildpath>
<buildpathentry kind="con" path="com.zend.php.phpunit.CONTAINER"/>
<buildpathentry kind="con" path="org.eclipse.php.core.LANGUAGE"/>
<buildpathentry kind="src" path=""/>
<buildpathentry kind="con" path="org.zend.php.framework.CONTAINER"/>
<bu
ildpath>
实际上就是在build的时候增加库的搜索。
网上搜到的文章也是类似的解决思路,如:ZendStudio ZS PHP函数黄色叹号问题.
不过我现在还用了php 进程控制的一些函数,没有被识别出来,后续看看在哪里可以添加相关的库。
2012年6月7日星期四
Gcc编译可变参数函数之__attribute__属性
这篇文章又是为了纪念我碰到的无数坑中的一个。话说在其他部门做项目的时候,还是全新的代码,某天就碰到一个程序崩溃问题,通过代码走查和屏蔽代码的方法,发现是程序里面的log函数造成的,log函数有可变参数,由于在写参数的时候没注意参数匹配,会出现类型不匹配或者数目不匹配的情况,然后makefile又没有编译warning,这些可好,编译出来的都正常,结果一跑就异常。还好现在的代码不多,如果是几万,几十万行的代码,找这样一个错误非要找死人啊。我一直不太理解,为什么代码编译时都不编译warning呢,要知道,经常可以在看warning的过程中发现代码的问题啊。
话说回来,如果仅仅是在gcc编译的时候加上-Wall选项,编译时是检查不出来可变参数不匹配的问题的。我也是google了好久才发现gcc一个特性__attribute__,可以用来解决此种问题。
首先:
__attribute__语法格式为:
__attribute__ ((attribute-list))
其位置约束为:
放于声明的尾部“;”之前。attribute-list可以有很多种,这里主要说format这个属性。
具体的含义如下:
__attribute__ format
该__attribute__属性可以给被声明的函数加上类似printf 或者scanf 的特征,它可以使编译器检查函数声明和函数实际调用参数之间的格式化字符串是否匹配。该功能十分有用,尤其是处理一些很难发现的bug。
format 的语法格式为:
format (archetype, string-index, first-to-check)
format 属性告诉编译器,按照printf, scanf, strftime 或strfmon 的参数表格式规则对该函数的参数进行检查。“archetype”指定是哪种风格;“string-index”指定传入函数的第几个参数是格式化字符串;“first-to-check”指定从函数的第几个参数开始按上述规则进行检查。
具体使用格式如下:
__attribute__((format(printf,m,n)))
__attribute__((format(scanf,m,n)))
其中参数m 与n 的含义为:
m:第几个参数为格式化字符串(format string);
n:参数集合中的第一个,即参数“…”里的第一个参数在函数参数总数排在第几,注意,有时函数参数里还有“隐身”的呢。
m和n的含义一不小心很容易搞错,我就是在这错了很多次,编译一直通不过。
比如说我自己写的一个函数:extern void WriteLog(const char *LogStr,...);
在使用时就是这样:WriteLog("info: %s %d",string info,int num);
那么传入函数的格式化字符串就是:"info: %s %d",即m为1。我们要检查是否匹配的第一个参数就是string info,这个参数在整个函数的参数集合里面位于第二位,所以n就是2。因此就要写成
extern void WriteLog(const char *LogStr,...) __attribute__((format(printf,1,2)));
如果这个函数是一个类的成员函数,由于成员函数默认带this指针,所以m和n的值就要加1,写法就变成:
void WriteLog(const char *LogStr,...) __attribute__((format(printf,2,3)));
由于是类的成员函数,所以上面的写法放在h文件里面就可以了。
如果m和n的值写错,gcc会提示你n不能小于m啊,或者m的值不是对应的格式化字符串等等。把函数写好后,再加上-Wall选项,这个就会提示warning了。不过我现在还不知道可以让出现这种warning的时候把它当error来处理,虽然有选项可以让所有的warning视为error,但是有些warning是允许存在的,怎么区分这类warning呢?这个留待以后吧。
另:gcc __attribute__属性的文档放到google drive里面了。嗯,我还真是个google控,但是google+ 界面太烂了。
话说回来,如果仅仅是在gcc编译的时候加上-Wall选项,编译时是检查不出来可变参数不匹配的问题的。我也是google了好久才发现gcc一个特性__attribute__,可以用来解决此种问题。
首先:
__attribute__语法格式为:
__attribute__ ((attribute-list))
其位置约束为:
放于声明的尾部“;”之前。attribute-list可以有很多种,这里主要说format这个属性。
具体的含义如下:
__attribute__ format
该__attribute__属性可以给被声明的函数加上类似printf 或者scanf 的特征,它可以使编译器检查函数声明和函数实际调用参数之间的格式化字符串是否匹配。该功能十分有用,尤其是处理一些很难发现的bug。
format 的语法格式为:
format (archetype, string-index, first-to-check)
format 属性告诉编译器,按照printf, scanf, strftime 或strfmon 的参数表格式规则对该函数的参数进行检查。“archetype”指定是哪种风格;“string-index”指定传入函数的第几个参数是格式化字符串;“first-to-check”指定从函数的第几个参数开始按上述规则进行检查。
具体使用格式如下:
__attribute__((format(printf,m,n)))
__attribute__((format(scanf,m,n)))
其中参数m 与n 的含义为:
m:第几个参数为格式化字符串(format string);
n:参数集合中的第一个,即参数“…”里的第一个参数在函数参数总数排在第几,注意,有时函数参数里还有“隐身”的呢。
m和n的含义一不小心很容易搞错,我就是在这错了很多次,编译一直通不过。
比如说我自己写的一个函数:extern void WriteLog(const char *LogStr,...);
在使用时就是这样:WriteLog("info: %s %d",string info,int num);
那么传入函数的格式化字符串就是:"info: %s %d",即m为1。我们要检查是否匹配的第一个参数就是string info,这个参数在整个函数的参数集合里面位于第二位,所以n就是2。因此就要写成
extern void WriteLog(const char *LogStr,...) __attribute__((format(printf,1,2)));
如果这个函数是一个类的成员函数,由于成员函数默认带this指针,所以m和n的值就要加1,写法就变成:
void WriteLog(const char *LogStr,...) __attribute__((format(printf,2,3)));
由于是类的成员函数,所以上面的写法放在h文件里面就可以了。
如果m和n的值写错,gcc会提示你n不能小于m啊,或者m的值不是对应的格式化字符串等等。把函数写好后,再加上-Wall选项,这个就会提示warning了。不过我现在还不知道可以让出现这种warning的时候把它当error来处理,虽然有选项可以让所有的warning视为error,但是有些warning是允许存在的,怎么区分这类warning呢?这个留待以后吧。
另:gcc __attribute__属性的文档放到google drive里面了。嗯,我还真是个google控,但是google+ 界面太烂了。
Crontab 碰到的一些问题(环境变量,cmd)
之前在一台机器上配置得好好的,昨天换了一台机器,然后配置的时候怎么都不行,郁闷。现象:配置后crontab后,程序没有运行。
尝试解决之:首先是怀疑crontab的服务没有启动,因为没有root权限,不能用命令看crontab状态,问同事,同事说crontab是默认启动的,然后我ps -ef|grep cron一把,发现cron是在跑的。这就不懂了,因为程序里面是有写log的,但是log文件可以看出来程序一直没跑。再问同事,然后他加了一条cmd在crontab里面:echo "1" 1>/home/temp.log,过了一会这个log文件就有内容了,可以看出来cron服务是正常运行的。这就怪了,我的程序是一个很简单的程序啊,怎么就跑不起来。当时同事说一般这种问题都是环境变量引起的。我的程序是使用了mysql库,但是我在shell里面直接运行都可以,应该不存在环境变量的问题吧。(就是这个想法导致我后来绕了一个大弯)。
到这个时候,我开始怀疑是不是在cron里面程序的标准输出被重定向了啊,其实程序是运行了的呢(这里我没有先想办法确定程序是否运行)。所以我就写了个简单的测试程序,就是main函数里面只有一个printf("test"),然后在crontab里面配置cmd为:/home/test 1>/home/test.log,稍等了一下,log文件马上就有内容了,这下看来是程序有问题了。我把自己的程序main函数改成只有一个打印语句,居然还是不行,怒了。难道是编译的时候有的库有问题(这里我已经走远了。。),为了证实这个,我改makefile,一个个库来编译(当时都居然没想到二分法!),最后终于发现是只要编译了mysqlclient库就有问题(我已经走远到天涯海角了),然后上网google之,还是没发现类似的问题啊。
百思不得其解,然后突然想到看别人的crontab配置里面有这样一句:2>&1,意思就是说标准错误信息和标准输出一样可以被重定向到一个文件,也许这个可以让我看看有没有出错信息呢。加上,马上发现程序运行时提示找不到mysql库,这下我终于想到是环境变量的问题了。由于我没有root权限,不能直接在/etc/crontab里面加上环境变量。所以就要写一个运行脚本,在脚本里面export LD_LIBRARY_PATH=/data/lib,然后在脚本里面调用程序。cron配置的时候就运行这个脚本就可以了。
修改完,过一会居然还有错,提示找不到程序文件。嗯,我在脚本里面调用程序用的是"./"这个相对路径来调用程序,但是crontab里面用的是用绝对路径来找运行脚本,比如:/home/auto_run.sh,这样就导致找不到程序文件了。修改成:cd /home;./auto_run.sh,有cd /home这句命令后,就可以改变当前目录,然后可以找到程序文件了。这下终于可以了。
回想这个问题,还真是绕了不少弯啊,主要是没有利用1>/home/temp.log 2>&1这种来查看输出。因为cron是一个守护进程,它设计成为捕捉所有的stdout和stderr然后mail给用户(这个没看cron的源代码,估计也是这样),所以在crontab里面只配置echo是不行的,必须把stdout重定向到文件,这样就可以了。
尝试解决之:首先是怀疑crontab的服务没有启动,因为没有root权限,不能用命令看crontab状态,问同事,同事说crontab是默认启动的,然后我ps -ef|grep cron一把,发现cron是在跑的。这就不懂了,因为程序里面是有写log的,但是log文件可以看出来程序一直没跑。再问同事,然后他加了一条cmd在crontab里面:echo "1" 1>/home/temp.log,过了一会这个log文件就有内容了,可以看出来cron服务是正常运行的。这就怪了,我的程序是一个很简单的程序啊,怎么就跑不起来。当时同事说一般这种问题都是环境变量引起的。我的程序是使用了mysql库,
到这个时候,
百思不得其解,然后突然想到看别人的crontab配置里面有这样一句:2>&1,意思就是说标准错误信息和标准输出一样可以被重定向到一个文件,也许这个可以让我看看有没有出错信息呢。加上,马上发现程序运行时提示找不到mysql库,这下我终于想到是环境变量的问题了。由于我没有root权限,不能直接在/etc/crontab里面加上环境变量。所以就要写一个运行脚本,在脚本里面export LD_LIBRARY_PATH=/data/lib,然后在脚本里面调用程序。cron配置的时候就运行这个脚本就可以了。
修改完,过一会居然还有错,提示找不到程序文件。嗯,我在脚本里面调用程序用的是"./"这个相对路径来调用程序,但是crontab里面用的是用绝对路径来找运行脚本,比如:/home/auto_run.sh,这样就导致找不到程序文件了。修改成:cd /home;./auto_run.sh,有cd /home这句命令后,就可以改变当前目录,然后可以找到程序文件了。这下终于可以了。
回想这个问题,还真是绕了不少弯啊,主要是没有利用1>/home/temp.log 2>&1这种来查看输出。因为cron是一个守护进程,它设计成为捕捉所有的stdout和stderr然后mail给用户(这个没看cron的源代码,估计也是这样),所以在crontab里面只配置echo是不行的,必须把stdout重定向到文件,这样就可以了。
2012年6月6日星期三
linux crontab 设置定时运行
因为这段时间做的程序都是要设置成为按固定时间运行,所以必须要对crontab进行一些配置。下面这篇文章说得不错,记录之。原帖地址:crontab 简介
命令简介
crontab命令常见于Unix和类Unix的操作系统之中,用于设置周期性被执行的指令。该命令从标准输入设备读取指令,并将其存放于“crontab”文件中,以供之后读取和执行。该词来源于希腊语 chronos(χρόνος),原意是时间。
通常,crontab储存的指令被守护进程激活, crond常常在后台运行,每一分钟检查是否有预定的作业需要执行。这类作业一般称为cron jobs。
crontab文件
crontab文件包含送交cron守护进程的一系列作业和指令。每个用户可以拥有自己的crontab文件;同时,操作系统保存一个针对整个系统的crontab文件,该文件通常存放于/etc或者/etc之下的子目录中,而这个文件只能由系统管理员来修改。
crontab文件的每一行均遵守特定的格式,由空格或tab分隔为数个领域,每个领域可以放置单一或多个数值。
使用说明
语法介绍
使用权限: root用户和crontab文件的所有者
crontab格式语法:
crontab [-e [UserName]|-l [UserName]|-r [UserName]|-v [UserName]|File ]
说明:
crontab 是用来让使用者在固定时间或固定间隔执行程序之用,换句话说,也就是类似使用者的时程表。-u user 是指设定指定 user 的时程表,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。如果不使用 -u user 的话,就是表示设定自己的时程表。
参数:
-e [UserName]: 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv VISUAL joe)
-r [UserName]: 删除目前的时程表
-l [UserName]: 列出目前的时程表
-v [UserName]:列出用户cron作业的状态
时程表的格式如下:
f1 f2 f3 f4 f5 program
其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行的程式。
当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程式,其余类推
当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其余类推
当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其余类推
当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其余类推
使用者也可以将所有的设定先存放在档案 file 中,用 crontab file 的方式来设定时程表。
由于unix版本不一样,所以部分语法有差别,例如在hp unix aix 中设定间隔执行如果采用*/n 方式将出现语法错误,在这类unix中 ,间隔执行只能以列举方式,详请见例子。
使用方法:
用VI编辑一个文件 cronfile,然后在这个文件中输入格式良好的时程表。编辑完成后,保存并退出。
在命令行输入
$: crontab cronfile
这样就将cronfile文件提交给c r o n进程,同时,新创建cronfile的一个副本已经被放在/ v a r / s p o o l / c r o n目录中,文件名就是用户名。
例子:
每月每天每小时的第 0 分钟执行一次 /bin/ls :
0 * * * * /bin/ls
在 12 月内, 每天的早上 6 点到 12 点中,每隔 20 分钟执行一次 /usr/bin/backup :
*/20 6-11 * 12 * /usr/bin/backup
周一到周五每天下午 5:00 寄一封信给 alex_mail_name :
0 17 * * 1-5 mail -s "hi" alex_mail_name < /tmp/maildata
每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha"
20 0-23/2 * * * echo "haha"
晚上11点到早上8点之间每两个小时,早上8点
0 23-7/2,8 * * * date
在hp unix,中,每20分钟执行一次,表示为:0,20,40 * * * * 而不能采用*/n方式,否则出现语法错误
注意:
1. 当程式在你所指定的时间执行后,系统会寄一封信给你,显示该程式执行的内容,若是你不希望收到这样的信,请在每一行空一格之后加上 > /dev/null 2>&1 即可。
2. %在crontab中被认为是newline,要用\来escape才行。比如crontab执行行中,如果有"date +%Y%m%d",必须替换为:"date +\%Y\%m\%d"
创建crontab?
在考虑向cron进程提交一个crontab文件之前,首先要做的一件事情就是设置环境变量EDITOR。cron进程根据它来确定使用哪个编辑器编辑crontab文件。99 %的UNIX和LINUX用户都使用vi,如果你也是这样,那么你就编辑$HOME目录下的.profile文件,在其中加入这样一行:
EDITOR=vi; export EDITOR
然后保存并退出。
不妨创建一个名为<user>cron的文件,其中<user>是用户名,为了提交你刚刚创建的crontab文件,可以把这个新创建的文件作为cron命令的参数:
$ crontab davecron
现在该文件已经提交给cron进程,同时,新创建文件的一个副本已经被放在/var/spool/cron目录中,文件名就是用户名(即,dave)。
列出crontab文件
为了列出crontab文件,可以用:
$crontab -l
编辑crontab文件
如果希望添加、删除或编辑crontab文件中的条目,而EDITOR环境变量又设置为vi,那么就可以用vi来编辑crontab文件,相应的命令为:
$ crontab -e
可以像使用vi编辑其他任何文件那样修改crontab文件并退出。
删除crontab文件
为了删除crontab文件,可以用:
$ crontab -r
恢复丢失的crontab文件
如果不小心误删了crontab文件,假设你在自己的$HOME目录下还有一个备份,那么可以将其拷贝到/var/spool/cron/<username>,其中<username >是用户名。如果由于权限问题无法完成拷贝,可以用:
$ crontab <filename>
其中,<filename>是你在$HOME目录中副本的文件名。
crontab中的输出配置
crontab中经常配置运行脚本输出为:>/dev/null 2>&1,来避免crontab运行中有内容输出。
shell命令的结果可以通过‘> ’的形式来定义输出
/dev/null 代表空设备文件
> 代表重定向到哪里,例如:echo "123" > /home/123.txt
1 表示stdout标准输出,系统默认值是1,所以">/dev/null"等同于"1>/dev/null"
2 表示stderr标准错误
& 表示等同于的意思,2>&1,表示2的输出重定向等同于1
那么重定向输出语句的含义:
1>/dev/null 首先表示标准输出重定向到空设备文件,也就是不输出任何信息到终端,不显示任何信息。
2>&1 表示标准错误输出重定向等同于标准输出,因为之前标准输出已经重定向到了空设备文件,所以标准错误输出也重定向到空设备文件。
2012年5月31日星期四
一个空string引发的血案
这确实是一个血案啊。linux下跑程序,由于是通过脚本来调用程序,结果程序崩溃时没看到通常的segment fault,只有崩溃前的log。然后仔细看了一下代码,很容易就发现问题所在。
代码是这样的:
这样看来,这个问题其实很简单,但是今天花时间主要是在看stl的代码上面,从研究生做完项目以后,我就没看到stl代码了,今天看了好一阵,太费劲了。每次看stl源码都有点生不如死的感觉啊。
代码是这样的:
1 string send_charac_name_org = "aa";
2 string send_charac_name = testfunc((char*)send_charac_name.c_str());
其实就是一个笔误,两处红色的地方不一致导致的。不过本着刻苦钻研的精神,我还是仔细研究了一下。2 string send_charac_name = testfunc((char*)send_charac_name.c_str());
- 首先,程序为什么崩溃,在testfunc里面打印,发现传进去的参数是一个0地址,所以必然崩溃了。
- c_str()是返回string变量的一个指针,在sgi版本的stl里面,这个指针_M_start指向string变量的首字符。那就是说这个指针是0,才导致的崩溃了。c_str()通常返回的是const char*,这里强制变为char *。
- 按理说定义了一个变量后,应该会分配内存,string里面的指针应该不为空的。说明这种写法 send_charac_name 还处于声明结束,没有定义完成啊。所以我换了个写法:1 string send_charac_name ;2 send_charac_name =testfunc((char*)send_charac_name.c_str());
这样就不会出现0地址了,说明string变量已经分配完内存了。
为了进一步搞清楚,又把stl的代码拿来看了一下,string的基类初始化时是没有分配内存的,只是把_M_start,_M_finish,_M_end_of_storage三个指针置为0了,只有到分配内存的时候才回设置三个指针。string变量定义完成后,sgi的版本是默认分配了8个字节的内存的。
这样看来,这个问题其实很简单,但是今天花时间主要是在看stl的代码上面,从研究生做完项目以后,我就没看到stl代码了,今天看了好一阵,太费劲了。每次看stl源码都有点生不如死的感觉啊。
使用dev-c++调试程序(包括gcc调试选项说明)
一般来说我调试的时候感觉用printf就足够了,不过今天想换换,用dev-c++来调试看看,没想到一直提示工程没有调试信息,后来在网上搜了一下,有好几种方法,试了一下,以下这种方法比较靠谱。我用的是方法2,也是可行的。
方法1:(已验证)
在“工具”-》编译选项-》"Add following commands when calling complier"下面的编辑框里加上: -g3
然后在下面的"Add these commands to the linker command line" 下的编辑框上加上: -g3
转到programs页,把gcc行修改为:gcc.exe -D__DEBUG__,
然后在下面的"Add these commands to the linker command line" 下的编辑框上加上: -g3
转到programs页,把gcc行修改为:gcc.exe -D__DEBUG__,
把g++行修改为: g++.exe -D__DEBUG__ ,
点击ok。
重新编译,就能调试了。
重新编译,就能调试了。
方法2:(本人未验证)
在dev c++ 环境中,写程序的时候,写了一个类,但是有点问题,想调试一下,但是调试的时候,老出现这个问题
your project does not have debugging info, do you want to enable debugging and rebuild your project?
在网上搜了一下解决方法
在 tools --> compiler options --> compiler, 有一个选项是:
Add these commands to the linker command line
将此选项勾选,并将内容 添加为 -g3 -gstabs
一些说明:
一些说明:
-gLevel 是gcc编译选项,level表示输出调试信息的级别,Level 3包含更多的信息,如程序中出现的所有宏定义.
-gstabsLevel stabs表示调试信息使用stabs格式。在gcc里面,支持多种格式的调试信息。
以下是对调试文件格式的一些说明:
调试文件格式(Debug File Formats)
调试可执行文件的时候,调试器需要使用由编译器生成的一些调试文件,这些信息将用户可读的变量名字与过程和数据地址联系起来。一般地,这些信息在程序执行时被舍去。调试程序时,这些信息很重要。Mac OS X使用两种调试文件格式,stabs和DWARF。stabs格式是Xcode 2.4之前的默认格式。DWARF是Xcode 2.4后的默认格式。stabs格式将调试信息贮存在可执行体的符号表中。参见Mac OS X ABI Mach-O File Format Refer-ence。DWARF格式则将其贮存在特殊的段中,或另一个调试信息文件。关于DWARF的更多信息,请看www.dwarfstd.org。关于stabs的更多信息,请看STABS Debug Format 。关于Mach-O文件和它的符号表,请看Mach-O Programming Topics 。
Dev-C++ 使用iconv
今天在调程序的时候,碰到一点问题,因为在linux下不太好调,所以就想在windows下面调一下,但是dev-c++没有iconv的头文件,也没有库,所以上网搜了一篇文章,弄了一下,就可以了。不过问题和iconv到没有什么关系。其实很简单,就是把iconv的库放到dev-c++的目录下,然后在编译的时候加搜索库的选项:-liconv ,这样编译就没问题了。
下面是摘抄:
==========================================
要使用 iconv 之前,我們需先對 Dev C++ 做一些前置工作,包括下載 iconv 元件,lib 載入,及一些 source code 修正等等。
首先是下載 iconv 元件,這裡的範例是使用這個,為了保證能正確運行,請下載一樣的版本。
http://www.d2school.com/cpp_lib_ex/iconv.rar
然後開啟 iconv.h ,找到第 88 行,把 const 前置詞去掉,這是因為不同的作業環境下而做的修正[1]。
extern LIBICONV_DLL_EXPORTED size_t iconv (iconv_t cd, const char* * inbuf, size_t *inbytesleft, char* * outbuf, size_t *outbytesleft);
把 const 前置詞去掉,像這樣。
extern LIBICONV_DLL_EXPORTED size_t iconv (iconv_t cd, char* * inbuf, size_t *inbytesleft, char* * outbuf, size_t *outbytesleft);
接著把一些相關的檔案複製到 Dev C++ 下的資料夾之中
copy iconv.dll C:\Dev-Cpp\bin
copy iconv.h C:\Dev-Cpp\include
copy libiconv.a C:\Dev-Cpp\lib
再來是設定載入 iconv,開啟 專案\專案選項\參數,並加上 -liconv ,如下圖
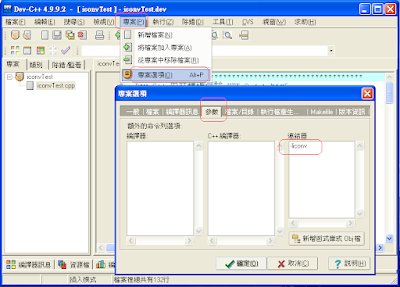
這樣就完成前置工作了,接著開個專案,把下面的代碼貼上,執行。
==========================
全文链接:Dev C++ 中文轉碼測試(UTF-8 to big5) Convert Code in Dev C++ Using iconv.
下面是摘抄:
==========================================
要使用 iconv 之前,我們需先對 Dev C++ 做一些前置工作,包括下載 iconv 元件,lib 載入,及一些 source code 修正等等。
首先是下載 iconv 元件,這裡的範例是使用這個,為了保證能正確運行,請下載一樣的版本。
http://www.d2school.com/cpp_lib_ex/iconv.rar
然後開啟 iconv.h ,找到第 88 行,把 const 前置詞去掉,這是因為不同的作業環境下而做的修正[1]。
extern LIBICONV_DLL_EXPORTED size_t iconv (iconv_t cd, const char* * inbuf, size_t *inbytesleft, char* * outbuf, size_t *outbytesleft);
把 const 前置詞去掉,像這樣。
extern LIBICONV_DLL_EXPORTED size_t iconv (iconv_t cd, char* * inbuf, size_t *inbytesleft, char* * outbuf, size_t *outbytesleft);
接著把一些相關的檔案複製到 Dev C++ 下的資料夾之中
copy iconv.dll C:\Dev-Cpp\bin
copy iconv.h C:\Dev-Cpp\include
copy libiconv.a C:\Dev-Cpp\lib
再來是設定載入 iconv,開啟 專案\專案選項\參數,並加上 -liconv ,如下圖

這樣就完成前置工作了,接著開個專案,把下面的代碼貼上,執行。
==========================
全文链接:Dev C++ 中文轉碼測試(UTF-8 to big5) Convert Code in Dev C++ Using iconv.
2012年5月17日星期四
GDB调试
昨天查问题的时候在网上搜索的,存一下吧。
============================
通过上面的解释,段错误应该就是访问了不可访问的内存,这个内存区要么是不存在的,要么是受到系统保护的。
后面有好多网友都跟帖了,讨论了Segmentation faults为什么这么“痛”,尤其是对于服务器程序来说,是非常头痛的,为了提高效率,要尽量减少一些不必要的段错误的“判断和处理”,但是不检查又可能会存在段错误的隐患。
编译和执行一下
Quote:
果然
我们“不小心”把&i写成了i
而我们刚开始初始化了i为0,这样我们不是试图向内存地址0存放一个值吗?实际上很多情况下,你即使没有初始化为零,默认也可能是0,所以要特别注意。
例子2:
很容易发现,这个例子也是试图往内存地址0处写东西。
2)内存越界(数组越界,变量类型不一致等)
Code:
#include <stdio.h>intmain(){ char test[1]; printf("%c", test[1000000000]); return 0;}
[Ctrl+A Select All]
这里是比较极端的例子,但是有时候可能是会出现的,是个明显的数组越界的问题
或者是这个地址是根本就不存在的
Code:
#include <stdio.h>intmain(){ int b = 10; printf("%s/n", b); return 0;}
[Ctrl+A Select All]
我们试图把一个整数按照字符串的方式输出出去,这是什么问题呢?
由于还不熟悉调试动态链接库,所以
我只是找到了printf的源代码的这里
Quote:
Code:
#include <stdio.h>#include <string.h>char c='c';int i=10;char buf[100];printf("%s", c); //试图把char型按照字符串格式输出,这里的字符会解释成整数,再解释成地址,所以原因同上面那个例子printf("%s", i); //试图把int型按照字符串输出memset(buf, 0, 100);sprintf(buf, "%s", c); //试图把char型按照字符串格式转换memset(buf, 0, 100);sprintf(buf, "%s", i); //试图把int型按照字符串转换
[Ctrl+A Select All]
参考资料[具体地址在上面的文章中都已经给出拉]:
原文地址 http://hi.baidu.com/lifeibest/blog/item/47c246e78d44ad2db93820a3.html
文章出处:飞诺网(www.firnow.com):http://dev.firnow.com/course/3_program/vc/vc_js/20090327/163598.html
[]
============================
最近一段时间在linux下用C做一些学习和开发,但是由于经验不足,问题多多。而段错误就是让我非常头痛的一个问题。不过,目前写一个一千行左右的代码,也很少出现段错误,或者是即使出现了,也很容易找出来,并且处理掉。
那什么是段错误?段错误为什么是个麻烦事?以及怎么发现程序中的段错误以及如何避免发生段错误呢?
一方面为了给自己的学习做个总结,另一方面由于至今没有找到一个比较全面介绍这个虽然是“particular problem”的问题,所以我来做个抛砖引玉吧。下面就从上面的几个问题出发来探讨一下“Segmentation faults"吧。
目录
1。什么是段错误?
2。为什么段错误这么“麻烦”?
3。编程中通常碰到段错误的地方有哪些?
4。如何发现程序中的段错误并处理掉?
2。为什么段错误这么“麻烦”?
3。编程中通常碰到段错误的地方有哪些?
4。如何发现程序中的段错误并处理掉?
正文
1。什么是段错误?
下面是来自Answers.com的定义:
Quote:
Quote:
A segmentation fault (often shortened to segfault) is a particular error condition that can occur during the operation of computer software. In short, a segmentation fault occurs when a program attempts to access a memory location that it is not allowed to access, or attempts to access a memory location in a way that is not allowed (e.g., attempts to write to a read-only location, or to overwrite part of the operating system). Systems based on processors like the Motorola 68000 tend to refer to these events as Address or Bus errors.
Segmentation is one approach to memory management and protection in the operating system. It has been superseded by paging for most purposes, but much of the terminology of segmentation is still used, "segmentation fault" being an example. Some operating systems still have segmentation at some logical level although paging is used as the main memory management policy.
On Unix-like operating systems, a process that accesses invalid memory receives the SIGSEGV signal. On Microsoft Windows, a process that accesses invalid memory receives the STATUS_ACCESS_VIOLATION exception.
所谓的段错误就是指访问的内存超出了系统所给这个程序的内存空间,通常这个值是由gdtr来保存的,他是一个48位的寄存器,其中的32位是保存由它指向的 gdt表,后13位保存相应于gdt的下标,最后3位包括了程序是否在内存中以及程序的在cpu中的运行级别,指向的gdt是由以64位为一个单位的表,在这张表中就保存着程序运行的代码段以及数据段的起始地址以及与此相应的段限和页面交换还有程序运行级别还有内存粒度等等的信息。一旦一个程序发生了越界访问,cpu就会产生相应的异常保护,于是segmentation fault就出现了
通过上面的解释,段错误应该就是访问了不可访问的内存,这个内存区要么是不存在的,要么是受到系统保护的。
2。为什么段错误这么麻烦?
中国linux论坛有一篇精华帖子《Segment fault 之永远的痛》(http://www.linuxforum.net/forum/gshowflat.php?Cat=&Board=program&Number=193239&page=2&view=collapsed&sb=5&o=all&fpart=1&vc=1)
在主题帖子里头,作者这么写道:
Quote:
在主题帖子里头,作者这么写道:
Quote:
写程序好多年了,Segment fault 是许多C程序员头疼的提示。指针是好东西,但是随着指针的使用却诞生了这个同样威力巨大的恶魔。
Segment fault 之所以能够流行于世,是与Glibc库中基本所有的函数都默认型参指针为非空有着密切关系的。
不知道什么时候才可以有能够处理NULL的glibc库诞生啊!
不得已,我现在为好多的函数做了衣服,避免glibc的函数被NULL给感染,导致我的Mem访问错误,而我还不知道NULL这个病毒已经在侵蚀我的身体了。
Segment fault 永远的痛......
后面有好多网友都跟帖了,讨论了Segmentation faults为什么这么“痛”,尤其是对于服务器程序来说,是非常头痛的,为了提高效率,要尽量减少一些不必要的段错误的“判断和处理”,但是不检查又可能会存在段错误的隐患。
那么如何处理这个“麻烦”呢?
就像人不可能“完美”一样,由人创造的“计算机语言“同样没有“完美”的解决办法。
我们更好的解决办法也许是:
就像人不可能“完美”一样,由人创造的“计算机语言“同样没有“完美”的解决办法。
我们更好的解决办法也许是:
通过学习前人的经验和开发的工具,不断的尝试和研究,找出更恰当的方法来避免、发现并处理它。对于一些常见的地方,我们可以避免,对于一些“隐藏”的地方,我们要发现它,发现以后就要及时处理,避免留下隐患。
下面我们可以通过具体的实验来举出一些经常出现段错误的地方,然后再举例子来发现和找出这类错误藏身之处,最后处理掉。
3。编程中通常碰到段错误的地方有哪些?
为了进行下面的实验,我们需要准备两个工具,一个是gcc,一个是gdb
我是在ubuntu下做的实验,安装这两个东西是比较简单的
Quote:
我是在ubuntu下做的实验,安装这两个东西是比较简单的
Quote:
sudo apt-get install gcc-4.0 libc6-dev
sudo apt-get install gdb
sudo apt-get install gdb
好了,开始进入我们的实验,我们粗略的分一下类
1)往受到系统保护的内存地址写数据
有些内存是内核占用的或者是其他程序正在使用,为了保证系统正常工作,所以会受到系统的保护,而不能任意访问。
例子1:
Code:
#include <stdio.h>intmain(){ int i = 0; scanf ("%d", i); /* should have used &i */ printf ("%d/n", i); return 0;}
[Ctrl+A Select All]
#include <stdio.h>intmain(){ int i = 0; scanf ("%d", i); /* should have used &i */ printf ("%d/n", i); return 0;}
[Ctrl+A Select All]
编译和执行一下
Quote:
咋一看,好像没有问题哦,不就是读取一个数据然后给输出来吗?
下面我们来调试一下,看看是什么原因?
Quote:
Quote:
falcon@falcon:~/temp$ gcc -g -o segerr segerr.c --加-g选项查看调试信息
falcon@falcon:~/temp$ gdb ./segerr
GNU gdb 6.4-debian
Copyright 2005 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i486-linux-gnu"...Using host libthread_db library "/ lib/tls/i686/cmov/libthread_db.so.1".
falcon@falcon:~/temp$ gdb ./segerr
GNU gdb 6.4-debian
Copyright 2005 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i486-linux-gnu"...Using host libthread_db library "/ lib/tls/i686/cmov/libthread_db.so.1".
(gdb) l --用l(list)显示我们的源代码
1 #include <stdio.h>
2
3 int
4 main()
5 {
6 int i = 0;
7
8 scanf ("%d", i); /* should have used &i */
9 printf ("%d/n", i);
10 return 0;
(gdb) b 8 --用b(break)设置断点
Breakpoint 1 at 0x80483b7: file segerr.c, line 8.
(gdb) p i --用p(print)打印变量i的值[看到没,这里i的值是0哦]
$1 = 0
1 #include <stdio.h>
2
3 int
4 main()
5 {
6 int i = 0;
7
8 scanf ("%d", i); /* should have used &i */
9 printf ("%d/n", i);
10 return 0;
(gdb) b 8 --用b(break)设置断点
Breakpoint 1 at 0x80483b7: file segerr.c, line 8.
(gdb) p i --用p(print)打印变量i的值[看到没,这里i的值是0哦]
$1 = 0
(gdb) r --用r(run)运行,直到断点处
Starting program: /home/falcon/temp/segerr
Starting program: /home/falcon/temp/segerr
Breakpoint 1, main () at segerr.c:8
8 scanf ("%d", i); /* should have used &i */ --[试图往地址0处写进一个值]
(gdb) n --用n(next)执行下一步
10
8 scanf ("%d", i); /* should have used &i */ --[试图往地址0处写进一个值]
(gdb) n --用n(next)执行下一步
10
Program received signal SIGSEGV, Segmentation fault.
0xb7e9a1ca in _IO_vfscanf () from /lib/tls/i686/cmov/libc.so.6
(gdb) c --在上面我们接收到了SIGSEGV,然后用c(continue)继续执行
Continuing.
0xb7e9a1ca in _IO_vfscanf () from /lib/tls/i686/cmov/libc.so.6
(gdb) c --在上面我们接收到了SIGSEGV,然后用c(continue)继续执行
Continuing.
Program terminated with signal SIGSEGV, Segmentation fault.
The program no longer exists.
(gdb) quit --退出gdb
The program no longer exists.
(gdb) quit --退出gdb
果然
我们“不小心”把&i写成了i
而我们刚开始初始化了i为0,这样我们不是试图向内存地址0存放一个值吗?实际上很多情况下,你即使没有初始化为零,默认也可能是0,所以要特别注意。
补充:
可以通过man 7 signal查看SIGSEGV的信息。
Quote:
可以通过man 7 signal查看SIGSEGV的信息。
Quote:
falcon@falcon:~/temp$ man 7 signal | grep SEGV
Reformatting signal(7), please wait...
SIGSEGV 11 Core Invalid memory reference
Reformatting signal(7), please wait...
SIGSEGV 11 Core Invalid memory reference
例子2:
Code:
#include <stdio.h>intmain(){ char *p; p = NULL; *p = 'x'; printf("%c", *p); return 0;}
[Ctrl+A Select All]
#include <stdio.h>intmain(){ char *p; p = NULL; *p = 'x'; printf("%c", *p); return 0;}
[Ctrl+A Select All]
很容易发现,这个例子也是试图往内存地址0处写东西。
这里我们通过gdb来查看段错误所在的行
Quote:
Quote:
falcon@falcon:~/temp$ gcc -g -o segerr segerr.c
falcon@falcon:~/temp$ gdb ./segerr
GNU gdb 6.4-debian
Copyright 2005 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i486-linux-gnu"...Using host libthread_db library "/lib/tls/i686/cmov/libthread_db.so.1".
falcon@falcon:~/temp$ gdb ./segerr
GNU gdb 6.4-debian
Copyright 2005 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i486-linux-gnu"...Using host libthread_db library "/lib/tls/i686/cmov/libthread_db.so.1".
(gdb) r --直接运行,我们看到抛出段错误以后,自动显示出了出现段错误的行,这就是一个找出段错误的方法
Starting program: /home/falcon/temp/segerr
Starting program: /home/falcon/temp/segerr
Program received signal SIGSEGV, Segmentation fault.
0x08048516 in main () at segerr.c:10
10 *p = 'x';
(gdb)
0x08048516 in main () at segerr.c:10
10 *p = 'x';
(gdb)
2)内存越界(数组越界,变量类型不一致等)
例子3:
Code:
#include <stdio.h>intmain(){ char test[1]; printf("%c", test[1000000000]); return 0;}
[Ctrl+A Select All]
这里是比较极端的例子,但是有时候可能是会出现的,是个明显的数组越界的问题
或者是这个地址是根本就不存在的
例子4:
Code:
#include <stdio.h>intmain(){ int b = 10; printf("%s/n", b); return 0;}
[Ctrl+A Select All]
我们试图把一个整数按照字符串的方式输出出去,这是什么问题呢?
由于还不熟悉调试动态链接库,所以
我只是找到了printf的源代码的这里
Quote:
声明部分:
int pos =0 ,cnt_printed_chars =0 ,i ;
unsigned char *chptr ;
va_list ap ;
%s格式控制部分:
case 's':
chptr =va_arg (ap ,unsigned char *);
i =0 ;
while (chptr [i ])
{...
cnt_printed_chars ++;
putchar (chptr [i ++]);
}
int pos =0 ,cnt_printed_chars =0 ,i ;
unsigned char *chptr ;
va_list ap ;
%s格式控制部分:
case 's':
chptr =va_arg (ap ,unsigned char *);
i =0 ;
while (chptr [i ])
{...
cnt_printed_chars ++;
putchar (chptr [i ++]);
}
仔细看看,发现了这样一个问题,在打印字符串的时候,实际上是打印某个地址开始的所有字符,但是当你想把整数当字符串打印的时候,这个整数被当成了一个地址,然后printf从这个地址开始去打印字符,指导某个位置上的值为/0。所以,如果这个整数代表的地址不存在或者不可访问,自然也是访问了不该访问的内存——segmentation fault。
类似的,还有诸如:sprintf等的格式控制问题
比如,试图把char型或者是int的按照%s输出或存放起来,如:
比如,试图把char型或者是int的按照%s输出或存放起来,如:
Code:
#include <stdio.h>#include <string.h>char c='c';int i=10;char buf[100];printf("%s", c); //试图把char型按照字符串格式输出,这里的字符会解释成整数,再解释成地址,所以原因同上面那个例子printf("%s", i); //试图把int型按照字符串输出memset(buf, 0, 100);sprintf(buf, "%s", c); //试图把char型按照字符串格式转换memset(buf, 0, 100);sprintf(buf, "%s", i); //试图把int型按照字符串转换
[Ctrl+A Select All]
3)其他
其实大概的原因都是一样的,就是段错误的定义。但是更多的容易出错的地方就要自己不断积累,不段发现,或者吸纳前人已经积累的经验,并且注意避免再次发生。
例如:
<1>定义了指针后记得初始化,在使用的时候记得判断是否为NULL
<2>在使用数组的时候是否被初始化,数组下标是否越界,数组元素是否存在等
<3>在变量处理的时候变量的格式控制是否合理等
<2>在使用数组的时候是否被初始化,数组下标是否越界,数组元素是否存在等
<3>在变量处理的时候变量的格式控制是否合理等
再举一个比较不错的例子:
我在进行一个多线程编程的例子里头,定义了一个线程数组
#define THREAD_MAX_NUM
pthread_t thread[THREAD_MAX_NUM];
用pthread_create创建了各个线程,然后用pthread_join来等待线程的结束
#define THREAD_MAX_NUM
pthread_t thread[THREAD_MAX_NUM];
用pthread_create创建了各个线程,然后用pthread_join来等待线程的结束
刚开始我就直接等待,在创建线程都成功的时候,pthread_join能够顺利等待各个线程结束,但是一旦创建线程失败,那用pthread_join来等待那个本不存在的线程时自然会存在访问不能访问的内存的情况,从而导致段错误的发生,后来,通过不断调试和思考,并且得到网络上资料的帮助,找到了上面的原因和解决办法:
在创建线程之前,先初始化我们的线程数组,在等待线程的结束的时候,判断线程是否为我们的初始值
如果是的话,说明我们的线程并没有创建成功,所以就不能等拉。否则就会存在释放那些并不存在或者不可访问的内存空间。
如果是的话,说明我们的线程并没有创建成功,所以就不能等拉。否则就会存在释放那些并不存在或者不可访问的内存空间。
上面给出了很常见的几种出现段错误的地方,这样在遇到它们的时候就容易避免拉。但是人有时候肯定也会有疏忽的,甚至可能还是会经常出现上面的问题或者其他常见的问题,所以对于一些大型一点的程序,如何跟踪并找到程序中的段错误位置就是需要掌握的一门技巧拉。
4。如何发现程序中的段错误?
有个网友对这个做了比较全面的总结,除了感谢他外,我把地址弄了过来。文章名字叫《段错误bug的调试》(http://www.cublog.cn/u/5251/showart.php?id=173718),应该说是很全面的。
而我常用的调试方法有:
1)在程序内部的关键部位输出(printf)信息,那样可以跟踪 段错误 在代码中可能的位置
为了方便使用这种调试方法,可以用条件编译指令#ifdef DEBUG和#endif把printf函数给包含起来,编译的时候加上-DDEBUG参数就可以查看调试信息。反之,不加上该参数进行调试就可以。
2)用gdb来调试,在运行到段错误的地方,会自动停下来并显示出错的行和行号
这个应该是很常用的,如果需要用gdb调试,记得在编译的时候加上-g参数,用来显示调试信息,对于这个,网友在《段错误bug的调试》文章里创造性的使用这样的方法,使得我们在执行程序的时候就可以动态扑获段错误可能出现的位置:通过扑获SIGSEGV信号来触发系统调用gdb来输出调试信息。如果加上上面提到的条件编译,那我们就可以非常方便的进行段错误的调试拉。
3)还有一个catchsegv命令
通过查看帮助信息,可以看到
Quote:
通过查看帮助信息,可以看到
Quote:
Catch segmentation faults in programs
这个东西就是用来扑获段错误的,不过打印出来的是一些register里头的东西,“看不太懂”。
到这里,“初级总结篇”算是差不多完成拉。欢迎指出其中表达不当甚至错误的地方,先谢过!
参考资料[具体地址在上面的文章中都已经给出拉]:
1。段错误的定义
Ansers.com
http://www.answers.com
Definition of "Segmentation fault"
http://www.faqs.org/qa/qa-673.html
2。《什么是段错误》
http://www.linux999.org/html_sql/3/132559.htm
3。《Segment fault 之永远的痛》
http://www.linuxforum.net/forum/gshowflat.php?Cat=&Board=program&Number=193239&page=2&view=collapsed&sb=5&o=all&fpart=
4。《段错误bug的调试》
http://www.cublog.cn/u/5251/showart.php?id=173718
Ansers.com
http://www.answers.com
Definition of "Segmentation fault"
http://www.faqs.org/qa/qa-673.html
2。《什么是段错误》
http://www.linux999.org/html_sql/3/132559.htm
3。《Segment fault 之永远的痛》
http://www.linuxforum.net/forum/gshowflat.php?Cat=&Board=program&Number=193239&page=2&view=collapsed&sb=5&o=all&fpart=
4。《段错误bug的调试》
http://www.cublog.cn/u/5251/showart.php?id=173718
后记
虽然感觉没有写什么东西,但是包括查找资料和打字,也花了好些几个小时,不过总结一下也是值得的,欢迎和我一起交流和讨论,也欢迎对文章中表达不当甚至是错误的地方指正一下
原文地址 http://hi.baidu.com/lifeibest/blog/item/47c246e78d44ad2db93820a3.html
文章出处:飞诺网(www.firnow.com):http://dev.firnow.com/course/3_program/vc/vc_js/20090327/163598.html
订阅:
评论 (Atom)